

Tagline
Die Tagline ist auch bekannt als Claim oder Slogan und schafft einen großen Wiedererkennungswert für Dein Unternehmen. Erfahre hier mehr! 💡 ... WeiterlesenTagline

noindex ist ein Attribut, welches im HTML-Code einer Website verwendet wird. Durch diesen Eintrag in den Metadaten teilst Du dem Googlebot beim Crawlen Deiner Website mit, dass er diese nicht in den Index mit aufnehmen soll. Das bedeutet im Umkehrschluss, dass diese Seite dann nicht in den SERPs bei Google gefunden werden kann. Du kannst dadurch direkt beeinflussen, welche Seiten Deiner Website gefunden werden sollen und welche nicht.
Webmaster nutzen diese Funktion zum Beispiel gerne für die Entwicklungsphase von Websites und entfernen den Tag, sobald die Seite online geht. Noindex wird ebenfalls verwendet, wenn sich Inhalte ähneln oder Doppelungen auftreten. Hierdurch wird Duplicate Content vermieden.
Durch die Aufnahme des Befehls „noindex“ in Deinen HTML Code, kannst Du verhindern, dass ungewünschte Seiten in den Suchergebnissen erscheint. Für die Umsetzung hast Du zwei Möglichkeiten:
Beim Crawlen der Website liest Google den Quellcode der Seite aus. Durch einen sogenannten X-Robots-Tag kannst Du den Robot anweisen, diese Seite nicht zu indexieren.
Beispiel für einen X-Robots-Tag:
| HTTP/1. 1 200 OK (…) X-Robots-Tag: noindex (…) |
Damit diese Variante der Implementierung funktioniert, muss der Meta-Tag im Head-Bereich des HTML Dokuments stehen.
Beispiel für einen Meta-Tag:
| <meta name= ‘‘robots“ content= ‘‘noindex“> |
In vielen CMS-Systemen, wie zum Beispiel WordPress, gibt es im Backend jedoch bereits entsprechende Funktionen, die das Implementieren des Tags durch Mausklick ermöglichen. Programmierkenntnisse sind für den Anwender hier nicht mehr zwingend notwendig.
Der Befehl „noindex“ kann durch die beiden Attribute „nofollow“ und „follow“ zusätzlich ergänzt werden.
Die Eigenschaft „nofollow“ gibt Google zusätzlich das Signal, dass die entsprechenden Links auf der Website nicht gecrawlt oder zu den verlinkenden Webseiten verknüpft werden sollen.
Das Merkmal „follow“ bewirkt genau das Gegenteil. Obwohl die Seite von Google nicht in den SERPs ausgespielt werden soll, erhält der Googlebot mit diesem Attribut den Hinweis, dass er den Links auf der Seite dennoch folgen soll. Von dieser Variante möchten wir Dir jedoch abraten, denn Du gibst Google dadurch keine klare Ansage, wie es die Seite und die darauf befindlichen Links behandeln soll.
John Müller schrieb hierzu auf dem WordPress Twitter Blog:
„I’d assume most people & search engines will take you by your word. „fine“ = ok, „noindex“ = don’t bother with this page. Sometimes more can happen („are you really fine?“, „what about this link?“), but the default is what you specify.“
Es macht durchaus Sinn einzelne Seiten Deiner Website von vornherein auf „noindex“ zu setzen. Hierzu zählen zum Beispiel:
Diese Seiten enthalten Informationen, die für den User Deiner Website zwar wichtig sind, jedoch von ihm nicht gezielt bei Google gesucht werden. Damit diese Seiten im Ranking nicht vor den wichtigen Inhalten Deiner Website landen, kannst Du diese mit gutem Gewissen auf „noindex“ setzen. Ebenfalls kannst Du hier Seiten mit ähnlichen oder doppelten Inhalten ausschließen.
Jede Website wird in regelmäßigen Abständen vom Googlebot gecrawlt. Hierdurch prüft Google, ob es neue Inhalte auf der Seite gibt oder die Website noch existiert. Wird von Dir eine Seite erst nachträglich auf „noindex“ gesetzt, so wird diese erst zeitverzögert aus dem Index genommen. Ein genaues Zeitfenster zu nennen, in welchem die Anpassungen übernommen werden, ist jedoch nicht möglich. Im Schnitt werden laut Google die Seiten spätestens nach 6 Monaten erneut besucht und gecrawlt. Dieser Faktor ist jedoch stark variabel, denn die Besuchshäufigkeit für URLs durch den Googlebot hängt mit einem eigens von Google konzipierten Algorithmus zusammen. Je nach Wichtigkeit der URL kann die Änderung auch bereits schon nach 14 Tagen übernommen worden sein.
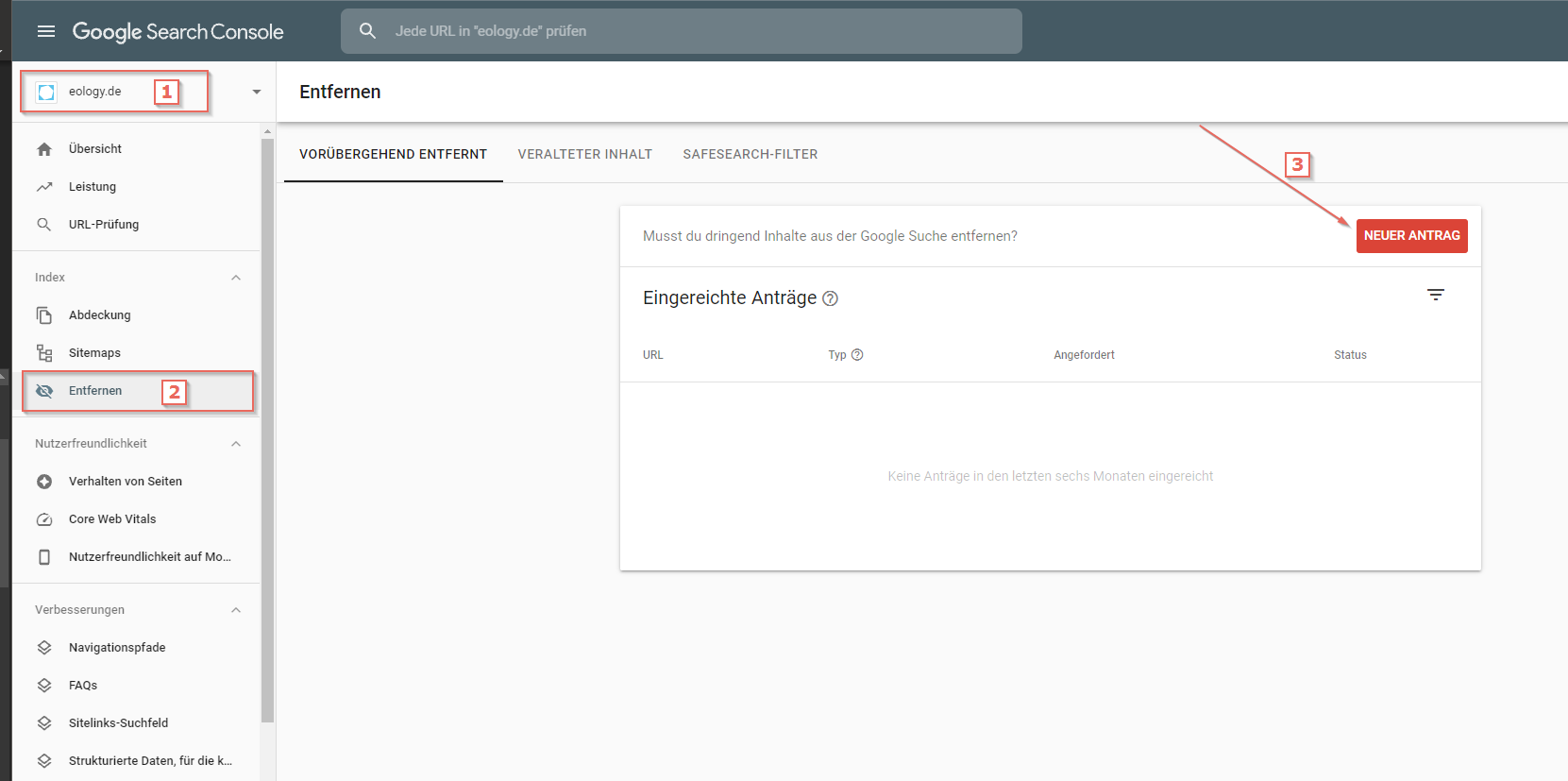
Solltest Du einmal eine URL aus den Google SERPs gelöscht haben wollen, so kannst Du hierfür einen Antrag stellen. Hierzu wird ein aktueller Zugang zur Google Search Console benötigt. Sobald Du eingeloggt bist, hast Du die Möglichkeit Deine „Property“ zu wählen. Anschließend wird der Punkt „Entfernen“ ausgewählt. Hier landest Du nun in dem Bereich, indem Du Deinen Antrag an Google stellen kannst. Deine angegebene Seite erscheint nun unter den eingereichten Anträgen und ist vorübergehend aus den Suchergebnissen entfernt. Sobald Dein Antrag geprüft wurde, verschiebt sich die Ansicht im besten Fall in den Reiter „Veralteter Inhalt“. Stelle diese Einträge zur Entfernung von URLs an Google nicht leichtfertig, denn dies ist endgültig.
Die Tagline ist auch bekannt als Claim oder Slogan und schafft einen großen Wiedererkennungswert für Dein Unternehmen. Erfahre hier mehr! 💡 ... WeiterlesenTagline
Im Online Marketing steht Dir ein breites Feld an Möglichkeiten zur Verfügung. Wie diese funktionieren und Du sie einsetzt erfährst du hier! ... WeiterlesenOnline Marketing
Website Header nennt man den sichtbaren Teil im obersten Bereich einer Webseite. Er enthält in der Regel wichtige Navigationselemente. ... WeiterlesenHeader
Du möchtest mehr über spannende Themen der Branche erfahren?